はじめに
3/19(金)に「Amazon S3 Object Lambda」というS3の新機能がGAになりました。
aws.amazon.com
これは上記公式サイトにも
「S3 から取得したデータをアプリケーションに返す前に独自のコードを追加して処理できる新機能」
とあるように、例えばS3バケットのキーをgetObjectする際に、あらかじめ何かの処理(フィルタリングやマスキングなど)を実施した値になっているため、getObject()を呼び出すLambdaでの変換処理が不要になります。
というわけで、今回はこのS3OLについて試してみた話です。
TL;DR
- S3OLの概要
- TypeScriptで実装してみた
- ハマった点など
S3OLの仕組み
S3OLの仕組みとしては、公式サイトの下の画像の通りです。
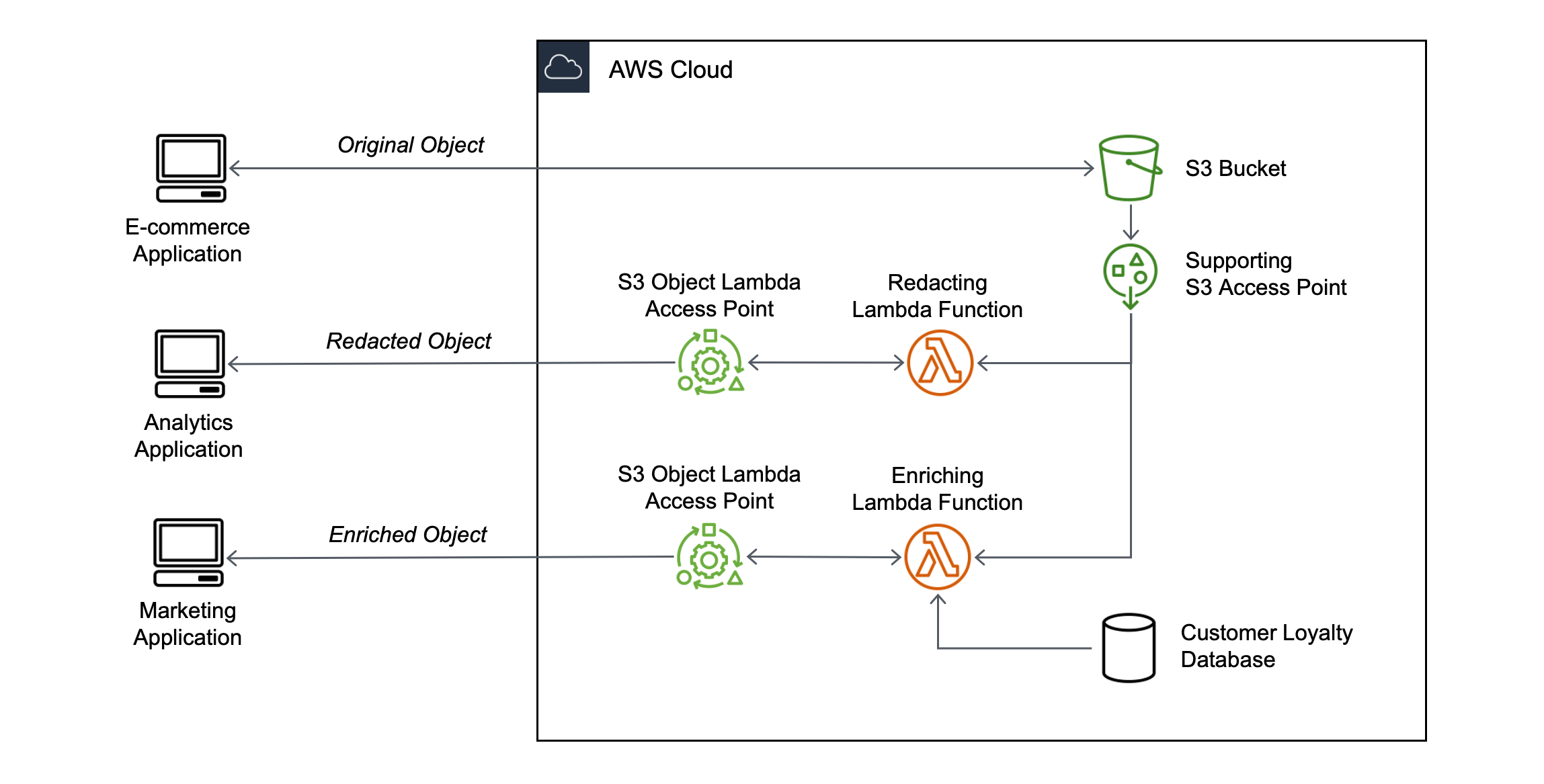
概要としては、こんな感じです。
- S3OLアクセスポイント経由でS3バケットにアクセスすると、S3OLにて変換処理をした値を取得できる
- S3OLアクセスポイントを経由しなければ、元の値(生値)を取得できる
- 1つのS3バケットについて、S3OLアクセスポイント(≒変換処理)を複数設定できる
ユースケースとしては、下記のようなケースです。
- 元の情報を編集して返す必要がある。
- (例) 特定の情報をフィルタ/マスクする、画像のサイズを変える...など
- 複数の処理(≒Lambda)で、上記のような処理を行う(=共通化)
参考サイト
実装してみる
というわけで、さっそく実装します。(今回はTypeScriptで実装)
前提条件として、aws-sdkを最新バージョンに更新しておきます。(最新バージョンじゃないとS3OLをサポートしていないので。Ver2.874.0でサポートを確認)
まずは「参考サイト」のAWS公式ブログに載っているコードを元に、TypeScriptで下記コードを書きました。(AWS公式ブログはpythonですが、全く問題なく理解できる内容だと思います。)
※元となる情報ですが、今回も「ドルアーガの塔 宝物リスト」のjsonを使用しています。(内容はこのブログの最後に載せています)
今回は「上記リスト(tower_of_druaga.json)から、階数(Floor)が素数の階の情報のみ取得する」という処理を実装しています。
import axios from 'axios'
import 'source-map-support/register';
import * as AWS from 'aws-sdk';
import S3 from 'aws-sdk/clients/s3';
interface IS3ObjectLambdaResponse {
statusCode: number
}
interface IObjectContext {
inputS3Url: string,
outputRoute: string,
outputToken: string
}
interface IDetail {
Condition: string,
Effect: string,
Memo: string,
Name: string
};
interface IFloor {
Type: string,
Floor: number,
Detail: IDetail[]
}
export async function handler(event:any): Promise<IS3ObjectLambdaResponse>{
console.log(`[event] ${JSON.stringify(event)}`);
const context:IObjectContext = event.getObjectContext;
const route:string = context.outputRoute;
const token:string = context.outputToken;
const url:string = context.inputS3Url
const res:any = await axios.get(url);
console.log(`[resData] ${JSON.stringify(res.data)}`);
const originalContent:IFloor[] = res.data;
const filteredContent:string = filter(originalContent);
const s3:S3 = new AWS.S3();
const param:S3.WriteGetObjectResponseRequest = {
RequestRoute: route,
RequestToken: token,
Body: filteredContent
};
const result = await s3.writeGetObjectResponse(param).promise();
const response:IS3ObjectLambdaResponse = {
statusCode: 200
}
return response;
}
function filter(_content:IFloor[]):string {
const filteredItem:IFloor[] = _content.filter(x => [2,3,5,7].findIndex(y => y === x.Floor) !== -1);
console.info(`[filteredItem] ${JSON.stringify(filteredItem)}`)
return JSON.stringify(filteredItem);
}
キーになるのは、「event.getObjectContext」で取得できる以下3つの値です。
| キー名 |
説明 |
備考 |
| outputRoute |
S3OLからLambdaに渡されるルーティングトークン |
writeGetObjectResponseで使用 |
| outputToken |
S3OLからLambdaに渡される認証(マッピング)トークン |
同上 |
| inputS3Url |
S3から元のキー内容を取得するためのURL |
|
これらをevent引数から取得したら、あとはソースにある通り、
- inputS3Urlにgetリクエストを投げて、そのレスポンスから元のキー内容を取得
- 「元のキー情報(=ファイル名)」はgetObjectの引数「key」で設定される
- 変換処理を実施し、元のキー情報から変換後の値を取得
- writeGetObjectResponse関数で、getObjectの戻り値を変換後の値に更新
- このLambda自体のレスポンスを返却する。(statusCode:200)
という処理を実施する感じです。
あとは上記Lambdaを、AWSに新規Lambda関数として作成しておいてください。
- コンソール直でも、CloudFormation(以下Cfn)経由でもどちらでもOKです。
- Cfnの場合、定義は通常のLambda関数と全く同じでOKです。
- もちろんServerless Frameworkも
また、上記S3OLのLambda関数を呼び出すLambda(s3_object_lambda_base.ts)も実装しました。
(詳細は省略しますが、レスポンスのBodyとして、「raw」にtower_of_druaga.jsonのそのままの値を、「filter」に先述の「階数(Floor)が素数の階のみの情報」を格納します。)
import { APIGatewayProxyEvent, APIGatewayProxyResult } from 'aws-lambda';
import 'source-map-support/register';
import { Context } from 'vm';
import * as AWS from 'aws-sdk';
import S3, { GetObjectRequest, GetObjectOutput } from 'aws-sdk/clients/s3';
interface IDetail {
Condition: string,
Effect: string,
Memo: string,
Name: string
};
interface IFloor {
Type: string,
Floor: number,
Detail: IDetail[]
}
export async function handler(event:APIGatewayProxyEvent, _context:Context):Promise<APIGatewayProxyResult> {
console.log(`[event] ${JSON.stringify(event)}`);
const s3:S3 = new AWS.S3();
const param_raw:GetObjectRequest = {
Bucket: 'suzukima-s3-object-lambda-test',
Key: 'tower_of_druaga.json'
};
const param_filtered:GetObjectRequest = {
Bucket: '<S3OLアクセスポイントのARN>',
Key: 'tower_of_druaga.json'
};
const result:IFloor[] = await Promise.all([s3getObject(s3, param_raw), s3getObject(s3, param_filtered)]);
const response:APIGatewayProxyResult = {
statusCode: 200,
body: JSON.stringify({
raw: result[0],
filtered: result[1]
})
}
return response;
}
async function s3getObject(_s3:S3, _param:GetObjectRequest):Promise<IFloor> {
const res:GetObjectOutput = await _s3.getObject(_param).promise();
console.info(`[res] ${JSON.stringify(res)}`);
return JSON.parse(res.Body.toString());
}
設定する(コンソール上で)
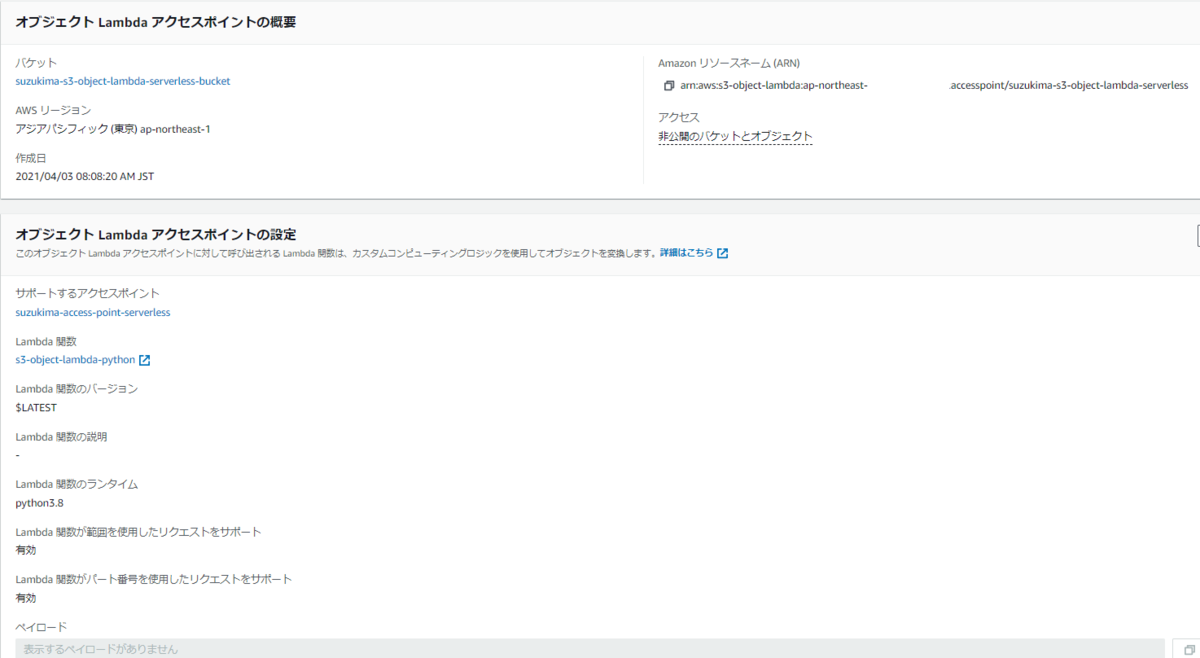
ということで、まずはS3OLをコンソール上で作成します。
といってもS3OLはS3アクセスポイントを必要とするので、まずはS3アクセスポイントを作成します。
コンソールから[S3]→[アクセスポイント]→[アクセスポイントの作成]と選択します。

| キー名 |
説明 |
備考 |
| アクセスポイント名 |
一意な名前を指定 |
|
| バケット名 |
対象のS3バケットを指定 |
「S3の参照」から選択可能 |
| ネットワークオリジン |
VPCかインターネットか。VPCならVPCIDも指定する。 |
今回は「インターネット」を指定 |
次に、S3OLのアクセスポイントを作成します。
コンソールから[S3]→[オブジェクトLambdaアクセスポイント]→[オブジェクトLambdaアクセスポイントの作成]と選択します。
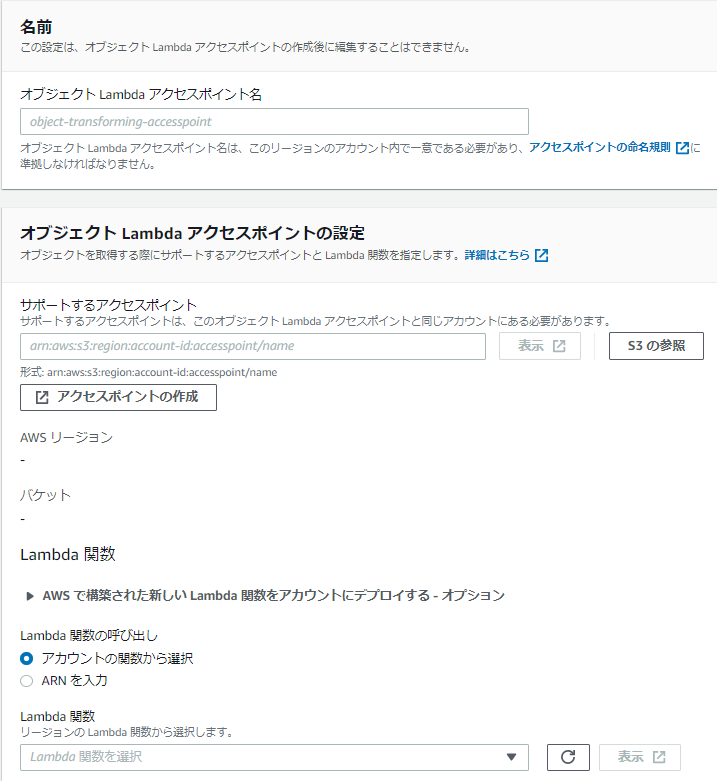
今回は下記項目のみ設定しました。(それ以外はデフォルトのまま)
| キー名 |
説明 |
備考 |
| オブジェクトLambdaアクセスポイント名 |
一意な名前を指定 |
|
| サポートするアクセスポイント |
対象のS3アクセスポイントのARNを指定 |
さっき作ったS3アクセスポイントのARN |
| Lambda関数の呼び出し |
呼び出すLambda関数を名前で指定するか、ARNで指定するか |
今回は「アカウントの関数から選択」を指定 |
| Lambda関数(のARN) |
「Lambda関数の呼び出し」の値に従い、関数名か関数のARNを指定 |
|
ここまで出来たら、動作を確認してみましょう。(今回はコンソール上で動作確認を行います)
動作確認は、コンソールから[S3]→[オブジェクトLambdaアクセスポイント]から上で作成したS3OLアクセスポイントを選択し、「オブジェクト」タブでキーをチェックして、「アクション」から「開く」を実施することで実施できます。
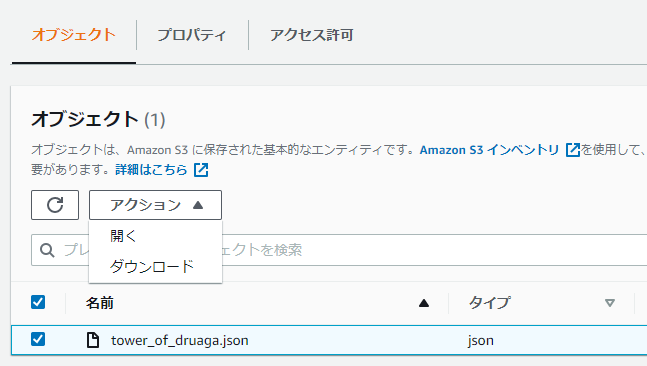
ハマった点など
「writeGetObjectResponse関数がない)」といわれる
これは参考サイトの クラスメソッドさんの記事にある通り、「AWS側のaws-sdkランタイムのバージョンが最新ではない」ことが原因です。
対策ですが、上記の記事通りに最新版のaws-sdkをLambdaレイヤーとして登録すればOKです。(Laambdレイヤーの説明は、今回は省略します)
結果が「Forbidden」になる
自分はこれにかなりハマりました。
結果としては、S3バケット&S3OLアクセスポイントへのポリシー設定で、下記のActionを許可すればOKです。
- S3バケット:s3:GetObject
- S3OLアクセスポイント:s3-object-lambda:WriteGetObjectResponse
ただ、僕が勘違いしてたのは、
- WriteGetObjectResponseを(S3OLアクセスポイントではなく)S3バケットに対して設定していた
- WriteGetObjectResponseを「s3:WriteGetObjectResponse」と勘違いしていた
点で、ここの調査にだいぶ時間を費やしてしまいました。(分かってしまえばなんてことはないんですけどね...)
結果
というわけで、最終的にs3_object_lambda_base.ts(AWS上ではjsだけど)を呼び出した結果が下の通り。
「raw」が「tower_of_druaga.json」そのままの値なのに対し、「filter」の方はちゃんとFloorが素数の情報のみになっています。
なので、S3OLが正しく動いている、と考えてよさそうです。
HTTP/1.1 200 OK
(中略)
{
"raw": [
{
"Type": "treasure",
"Floor": 1,
"Detail": [
{
"Condition": "グリーンスライムを3匹倒す",
"Effect": "壁を宝箱を取る前後1回ずつ壊せる",
"Memo": "",
"Name": "カッパーマトック"
}
]
},
{
"Type": "treasure",
"Floor": 2,
"Detail": [
{
"Condition": "ブラックスライムを2匹倒す",
"Effect": "足が速くなる",
"Memo": "",
"Name": "ジェットブーツ"
}
]
},
{
"Type": "treasure",
"Floor": 3,
"Detail": [
{
"Condition": "ブルーナイトのどちらかを倒す",
"Effect": "ミスしても残機が減らない(1回だけ)",
"Memo": "正確な条件は、「ブルーナイトのうち、先にフロアに出現した方を倒す」",
"Name": "ポーション・オブ・ヒーリング"
}
]
},
{
"Type": "treasure",
"Floor": 4,
"Detail": [
{
"Condition": "扉を通過する",
"Effect": "フロア開始時、鍵がある方向を向くと音が鳴る",
"Memo": "宝箱を出すより先に鍵を取ってしまうと出ない",
"Name": "チャイム"
}
]
},
{
"Type": "treasure",
"Floor": 5,
"Detail": [
{
"Condition": "メイジの呪文を歩きながら盾で3回受ける",
"Effect": "攻撃力UP",
"Memo": "18階のドラゴンスレイヤーを取るのに必要",
"Name": "ホワイトソード"
}
]
},
{
"Type": "treasure",
"Floor": 6,
"Detail": [
{
"Condition": "最上段に上がった後、下がる",
"Effect": "10階までゴーストが見えるようになる",
"Memo": "",
"Name": "キャンドル"
}
]
},
{
"Type": "treasure",
"Floor": 7,
"Detail": [
{
"Condition": "カッパーマトックをなくす",
"Effect": "宝箱を取る前に1回、取った後2回使える",
"Memo": "最大で宝箱を取る前に4回、取った後に5回まで使えるが、Effectの回数より多く使うと1/3の確率で壊れる",
"Name": "シルバーマトック"
}
]
},
{
"Type": "treasure",
"Floor": 8,
"Detail": [
{
"Condition": "ステート時点からX軸,Y軸共にずれた位置で剣を振る",
"Effect": "体力が上がる(その階のみ)",
"Memo": "",
"Name": "ポーション・オブ・パワー"
}
]
},
{
"Type": "treasure",
"Floor": 9,
"Detail": [
{
"Condition": " 最上段の右から8列目と左から8列目の両地点を通過する。",
"Effect": "体力が下がる(その階のみ)",
"Memo": "",
"Name": "ポーション・オブ・エナジー・ドレイン"
}
]
},
{
"Type": "treasure",
"Floor": 10,
"Detail": [
{
"Condition": "レッドスライムの放つ呪文を盾で受ける。",
"Effect": "26階の宝箱(ハイパーガントレット)を取るのに必要。",
"Memo": "レッドスライムの気分次第。",
"Name": "ガントレット"
}
]
}
],
"filtered": [
{
"Type": "treasure",
"Floor": 2,
"Detail": [
{
"Condition": "ブラックスライムを2匹倒す",
"Effect": "足が速くなる",
"Memo": "",
"Name": "ジェットブーツ"
}
]
},
{
"Type": "treasure",
"Floor": 3,
"Detail": [
{
"Condition": "ブルーナイトのどちらかを倒す",
"Effect": "ミスしても残機が減らない(1回だけ)",
"Memo": "正確な条件は、「ブルーナイトのうち、先にフロアに出現した方を倒す」",
"Name": "ポーション・オブ・ヒーリング"
}
]
},
{
"Type": "treasure",
"Floor": 5,
"Detail": [
{
"Condition": "メイジの呪文を歩きながら盾で3回受ける",
"Effect": "攻撃力UP",
"Memo": "18階のドラゴンスレイヤーを取るのに必要",
"Name": "ホワイトソード"
}
]
},
{
"Type": "treasure",
"Floor": 7,
"Detail": [
{
"Condition": "カッパーマトックをなくす",
"Effect": "宝箱を取る前に1回、取った後2回使える",
"Memo": "最大で宝箱を取る前に4回、取った後に5回まで使えるが、Effectの回数より多く使うと1/3の確率で壊れる",
"Name": "シルバーマトック"
}
]
}
]
}
まとめ
というわけで、S3OLの紹介&実際に動かしてみました。
今までモジュールなどで行っていましたが、これを使うことで、確かに便利なケースは出てきそうですね。 (例えば公式ブログにあった画像サイズ変換とか、あどクラスメソッドさんの記事にもあった文字コード変換とか)
なお、今回はS3OLの設定をコンソール上で行いましたが、その2ではこれはCloudFormation(実際はServerless Frameworkだけど)から定義・作成する方法を書こうと思っています。(serverless.tsの内容は、その際に公開します。)
告知
先日行われた「JAWS DAYS 2021 re:Connect」における、私のセッションのアーカイブ動画が公開されたしたので、よろしければご参照ください。
www.youtube.com
また、他の方の動画も公開されているので、見逃したという人も、この機会にぜひご覧ください。
それでは、今回はこの辺で
過去のServerless Meetup Japan VirtualやQiita Advent Calendar 2020などで使用している「ドルアーガの塔 宝物リスト」の内容になります。
(「ドルアーガの塔」がわからない人は、ググってみると幸せになれるかもしれません。)
内容としては、下記情報を格納したオブジェクトの配列になります。(実際は60階分あるけど、今回は10階まで用意)
| キー名 |
キー名(Detail内) |
説明 |
備考 |
| Type |
|
内容の種類 |
「treasure」固定。パーティションキー |
| Floor |
|
階数(1~60) |
ソートキー |
| Detail |
|
下記4項目が格納されたオブジェクトの配列 |
配列なのは、45階だけ宝物が2つあるから |
| |
Condition |
宝物の出現条件 |
|
| |
Effect |
宝物の効果。 |
|
| |
Memo |
一言メモ |
|
| |
Name |
宝物のアイテム名 |
一部微妙に違ってるかも |
[
{
"Type": "treasure",
"Floor": 1,
"Detail": [
{
"Condition": "グリーンスライムを3匹倒す",
"Effect": "壁を宝箱を取る前後1回ずつ壊せる",
"Memo": "",
"Name": "カッパーマトック"
}
]
},
{
"Type": "treasure",
"Floor": 2,
"Detail": [
{
"Condition": "ブラックスライムを2匹倒す",
"Effect": "足が速くなる",
"Memo": "",
"Name": "ジェットブーツ"
}
]
},
{
"Type": "treasure",
"Floor": 3,
"Detail": [
{
"Condition": "ブルーナイトのどちらかを倒す",
"Effect": "ミスしても残機が減らない(1回だけ)",
"Memo": "正確な条件は、「ブルーナイトのうち、先にフロアに出現した方を倒す」",
"Name": "ポーション・オブ・ヒーリング"
}
]
},
{
"Type": "treasure",
"Floor": 4,
"Detail": [
{
"Condition": "扉を通過する",
"Effect": "フロア開始時、鍵がある方向を向くと音が鳴る",
"Memo": "宝箱を出すより先に鍵を取ってしまうと出ない",
"Name": "チャイム"
}
]
},
{
"Type": "treasure",
"Floor": 5,
"Detail": [
{
"Condition": "メイジの呪文を歩きながら盾で3回受ける",
"Effect": "攻撃力UP",
"Memo": "18階のドラゴンスレイヤーを取るのに必要",
"Name": "ホワイトソード"
}
]
},
{
"Type": "treasure",
"Floor": 6,
"Detail": [
{
"Condition": "最上段に上がった後、下がる",
"Effect": "10階までゴーストが見えるようになる",
"Memo": "",
"Name": "キャンドル"
}
]
},
{
"Type": "treasure",
"Floor": 7,
"Detail": [
{
"Condition": "カッパーマトックをなくす",
"Effect": "宝箱を取る前に1回、取った後2回使える",
"Memo": "最大で宝箱を取る前に4回、取った後に5回まで使えるが、Effectの回数より多く使うと1/3の確率で壊れる",
"Name": "シルバーマトック"
}
]
},
{
"Type": "treasure",
"Floor": 8,
"Detail": [
{
"Condition": "ステート時点からX軸,Y軸共にずれた位置で剣を振る",
"Effect": "体力が上がる(その階のみ)",
"Memo": "",
"Name": "ポーション・オブ・パワー"
}
]
},
{
"Type": "treasure",
"Floor": 9,
"Detail": [
{
"Condition": " 最上段の右から8列目と左から8列目の両地点を通過する。",
"Effect": "体力が下がる(その階のみ)",
"Memo": "",
"Name": "ポーション・オブ・エナジー・ドレイン"
}
]
},
{
"Type": "treasure",
"Floor": 10,
"Detail": [
{
"Condition": "レッドスライムの放つ呪文を盾で受ける。",
"Effect": "26階の宝箱(ハイパーガントレット)を取るのに必要。",
"Memo": "レッドスライムの気分次第。",
"Name": "ガントレット"
}
]
}
]