はじめに
前回、および前々回の記事で、AWS AppsSync(以下「AppSync」)のOpenID Connect認証、およびLambda認証について書きました。
となれば今回はIAM認証かな...とも思ったんですが、今回はちょっと話題を変えて、自分も大好きなServerless FrameworkでAppSync APIを作成する方法について書きたいと思います。
TL;DR
- Serverless Frameworkでは、デフォルトではAppSyncはサポートされていない
- でも「serverless-appsync-plugin」を使えば、AppSyncを作成できる
- そのやり方
参考サイト
- serverless-appsync-plugin(GitHub)
- Serverless GraphQL with AppSync — Java and NodeJS Clients | by Vinod Kisanagaram | Sep, 2021 | Towards AWS
- https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/AWS_AppSync.html:title
serverless-appsync-pluginについて
現在(2021/9/26時点)、Serverless Frameworkの公式機能としては、AppSyncはサポートされておらず、Lambdaのトリガ元として設定することもできません。(リゾルバが必ずしもLambdaとは限らないので、当然と言えば当然ですが)
ですのでServerless Framework標準機能でAppSyncを作成する場合、resourcesセクションで、生のCloudFormation(以下「Cfn」)のテンプレートを記載する必要があります。
しかし、Serverless FrameworkのPluginとして「serverless-appsync-plugin」というものが公開されており、これを使うことで、生のCfn構文を書かなくてもServerless FrameworkでAppSyncを作成することができます。
早速使ってみる
というわけで、まずはインストールします。
以下コマンドでインストールを行います。
> npm install serverless-appsync-plugin --save-dev
そして、serverless.ymlの「plugins」セクションに「serverless-appsync-plugin」を追加します。
plugins: - serverless-appsync-plugin
serverless.ymlを見ながら説明
「百聞は一見に如かず」ということで、ここからは実際のserverless.ymlを元に説明します。(関係ない定義は省略)
また全部説明するとキリがないので、appSyncキーの子要素&重要ポイントだけ説明します。(各項目の詳細説明は「参考サイト」のGitHubページに全て書いてあります。)
なお今回は、
というAppSync APIを作成しています。
あとLambda関数「authL」「treasureL」の処理内容は、前回の記事のそれと全く同じです。
service: 'terraform-sample' frameworkVersion: '2' custom: appSync: name: appsync-plugin-sample-api2 # apiId: zn2mpenctja3neujg7m2vaiw3m authenticationType: AWS_LAMBDA schema: schema.graphql lambdaAuthorizerConfig: # functionName: # The function name in your serverless.yml. Ignored if lambdaFunctionArn is provided. # functionAlias: # optional, used with functionName lambdaFunctionArn: { Fn::GetAtt: [AuthLLambdaFunction, Arn] } # identityValidationExpression: # optional authorizerResultTtlInSeconds: 300 # openIdConnectConfig: # issuer: # clientId: # iatTTL: # authTTL: logConfig: loggingRoleArn: arn:aws:iam::659547760577:role/administratorRole level: ALL excludeVerboseContent: false defaultMappingTemplates: request: false response: false mappingTemplates: - type: Query request: false response: false dataSource: dataSourceLambda field: treasureL dataSources: - type: AWS_LAMBDA name: dataSourceLambda description: 'Lambda DataSource for appsync-plugin-sample-api2.' config: # Either of functionName or lambdaFunctionArn must tbe provided. When both are present, lambdaFunctionArn is used. # functionName: graphql lambdaFunctionArn: { Fn::GetAtt: [TreasureLLambdaFunction, Arn] } serviceRoleArn: arn:aws:iam::659547760577:role/administratorRole plugins: - serverless-appsync-plugin functions: treasureL: handler: ./dist/treasureL/index.handler authL: handler: ./dist/authL/index.handler
大前提として「custom」セクション内に「appSync」キーを設定し、その中にAppSync APIの定義を書いていきます。
また上記serverless.ymlではしていませんが、AppSync APIの定義を配列で複数個定義することにより、一度に複数個のAppSync APIを作成できます。(同一スタックで管理したい場合)
「appSync」キーには、下表のキーが設定できます。
なお、とりあえず新規にAppSync APIを作る場合、
- name/authenticationType/schemaを設定する
- authenticationTypeに対応した認証設定を該当キー(lambdaAuthorizerConfigなど)で行う
- dataSourcesでデータソースを定義する
- mappingTemplatesでリゾルバの定義&データソースとの紐づけ(Query/Mutation)を行う
の手順を踏めばOKです。
| 項目名 | 説明 | 備考 |
|---|---|---|
| name | AppSync APIのAPI名 | |
| apiKey | AppSync APIのAPI KEYの値 | 既存のAppSync APIの更新/削除時のみ必要。(新規作成時は不要) |
| apiId | AppSync APIのAPI IDの値 | 指定した場合、該当のAppSync APIのみ更新する(?)(新規作成時は不要) |
| authenticationType | APIの認証形式。API_KEY, AWS_IAM, AMAZON_COGNITO_USER_POOLS, OPENID_CONNECT, AWS_LAMBDAから選択 | AWS::AppSync::GraphQLApiのそれと同じ |
| schema | スキーマ定義ファイルのパス(globパターンでの指定可能) | デフォルトは「schema.graphql」 |
| caching | キャッシュの設定 | |
| userPoolConfig | 認証用Cognitoユーザープールの設定 | authenticationTypeで「AMAZON_COGNITO_USER_POOLS」を選んだ場合のみ反映される |
| lambdaAuthorizerConfig | 認証用Lambdaユーザープールの設定 | authenticationTypeで「AWS_LAMBDA」を選んだ場合のみ反映される |
| openIdConnectConfig | OIDC認証の設定 | authenticationTypeで「OPENID_CONNECT」を選んだ場合のみ反映される |
| apiKeys | 認証用API KEYの設定 | authenticationTypeで「API_KEY」を選んだ場合のみ反映される |
| additionalAuthenticationProviders | 「追加の認証プロバイダー」の設定 | |
| logConfig | 「ログ記録」の設定 | excludeVerboseContentは「詳細なコンテンツを含める」の設定(デフォルトはfalse) |
| defaultMappingTemplates | 「MappingTemplates」のrequest/responseのデフォルト設定 | ダイレクトLambdaリゾルバのように全部(または大部分)が同じ設定の場合、個々を設定すると個々の「mappingTemplates」で設定する必要がなくなる(あるいは省略できる) |
| mappingTemplates | リゾルバのデータソース、およびマッピングテンプレートの設定 | 配列形式 |
| functionConfigurations | AppSync関数の設定 | 配列形式。省略可 |
| dataSources | データソースの設定 | 配列形式 |
| substitutions | mappingTemplatesで指定した全リゾルバに渡す変数(variables)の設定 | |
| xrayEnabled | X-RAYの有効/無効の設定 | デフォルトはfalse(=無効) |
| wafConfig | WAF(AWS Web Application Firewall)の設定 |
※注意点
- 上記serverless.ymlや「参考サイト」のGitHubページを見るとわかる通り、省略可能な項目もあります。(上表はとりあえず一通りappSyncキーの子要素を洗いだしてあります)
- 「lambdaAuthorizerConfig」及び(dataSources.typeで「AWS_LAMBDA」を指定した場合の)「dataSources.config」では、Lambda関数を下記2つのキーのいずれかの方法で指定できます。
- functionName(Lambda関数名)
- lambdaFunctionArn(Lambda関数のARN)
- 上記はいずれか一方のみの指定となります。(両方指定した場合、lambdaFunctionArnが優先される)
実行結果
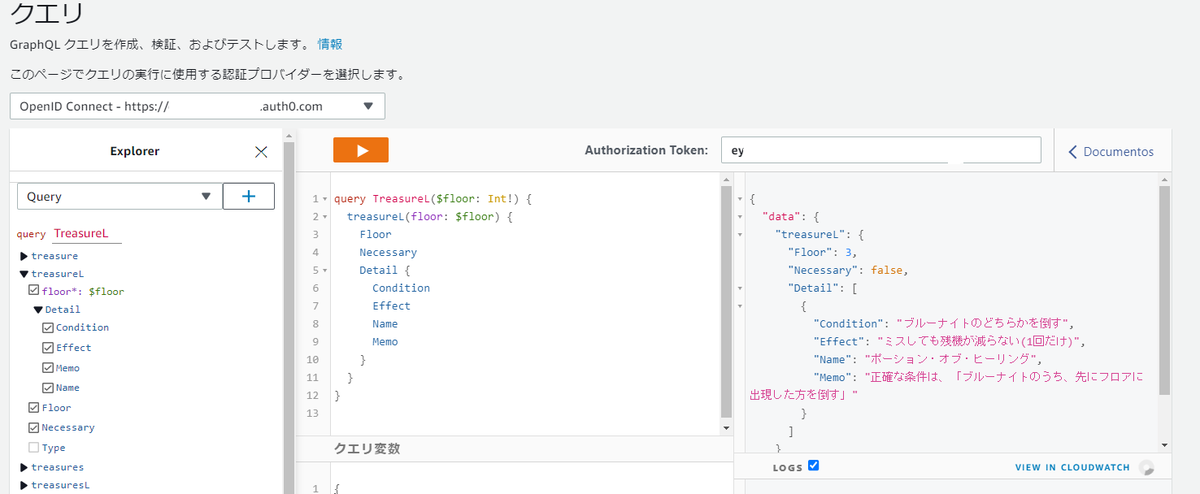
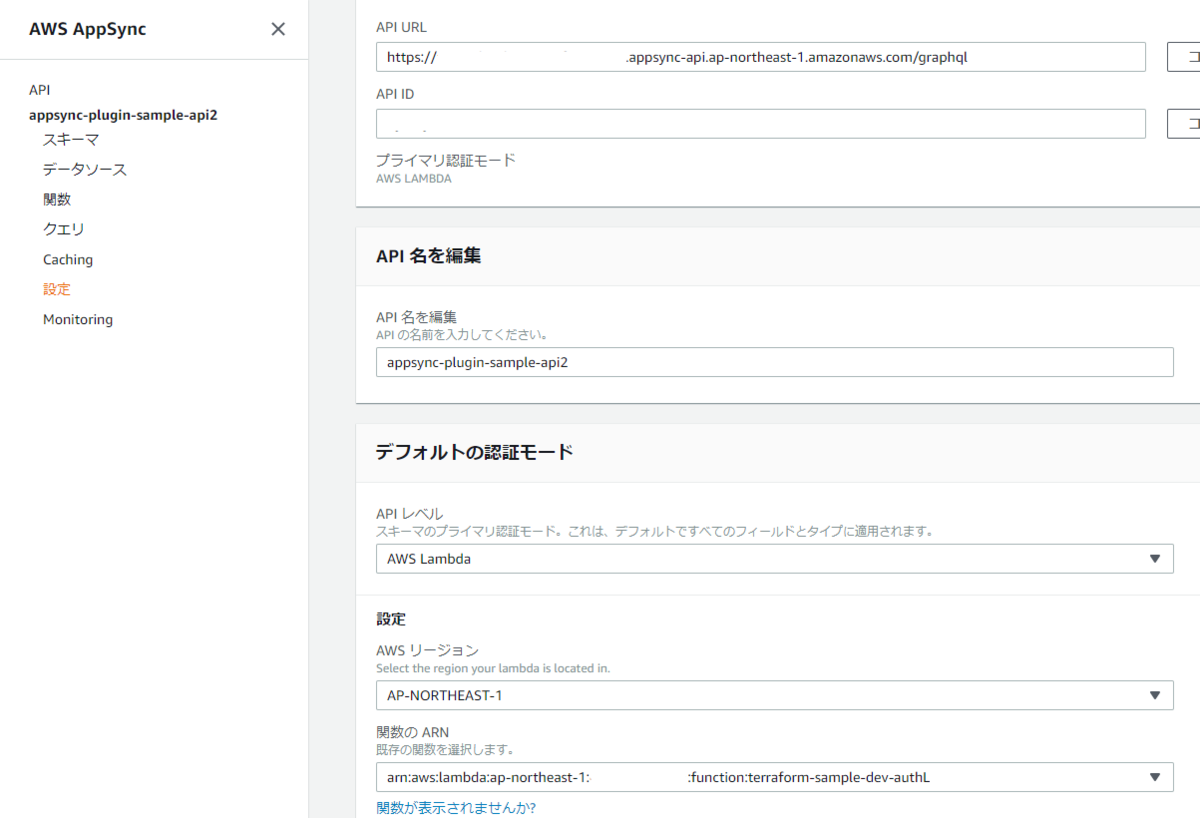
上記「serverless.ymlを見ながら説明」のserverless.ymlをデプロイした結果が以下の画像の通りです。
AppSync APIが作成され、設定も正しく反映されているのが分かります。

また、Rest Clientで実際にリクエストを投げてみても、ちゃんとLambda認証やリゾルバが正しく動いているのが分かります。


まとめ
以上、Serverless FrameworkでAppSync APIを作成する方法について書きました。
Serverless Frameworkは、こういう便利なPluginがたくさん公開されているので便利です。こういうのをどんどん利用して、環境構築を便利にしていきたいです。
てか、自分でもなんかPluginを作成&公開できるようになりたいなあ。(マジで。てはハンズオンとかあったら、有料でも参加したい...)
告知
私が昨年登壇した「VS Code Conference」ですが、今年もオンラインで開催されるそうです。
また、登壇受付も9/30(木)まで行っているそうなので、興味のある方は応募されてみてはいかがでしょうか?
ちなみに僕は、ネタがなかなか思い浮かばないのと、予定の関係で、今年はどうするか悩んでおります。
では、今回はこの辺で。